
JuHyang
Machine Learning ( Keras) 본문
https://tykimos.github.io/lecture/
가상 개발환경 만들기
conda create -n tf_gpu python=3.6 anaconda
가상 개발환경 실행
conda activatetf_gpu
텐서플로우 설치
pip install tensorflow
케라스 설치
pip install keras
> deactivate #가상환경 접속종료하기
> conda remove -n tf_gpu –all #가상환경 삭제/제거하기
tensorlow-gpu 사용을 위해서 nvidia cuda 를 설치해야 한다
10.1 버전으로 설치하면 오류 디지게 남 >> 10.0 으로 바꾸셈
https://itchipmunk.tistory.com/104
교제 예제 소스 : https://github.com/gilbutITbook/006958
[모두의 딥러닝] 02. 처음 해 보는 딥러닝
-
미지의 일을 예측하는 힘
-
기존 : 데이터 입력 -> 답을 구함
-
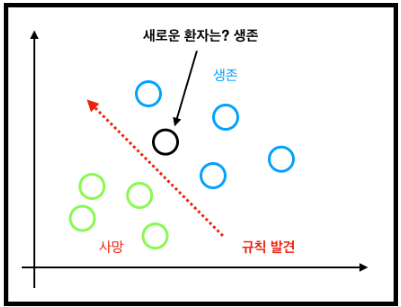
머신러닝 : 데이터 안에서 규칙을 발견 -> 새로운 데이터에 그 규칙 적용 -> 새로운 결과 도출

-
학습 : 데이터 입력 -> 패턴 분석 과정
-
1. 기존 환자 데이터 이볅
-
2, 머신러닝 학습
-
3. 새로운 환자 예측
>> 머신러닝의 예측 성공률 : 결국 얼마나 정확한 경계선을 긋는가
>> 방법 : 랜덤 포레스트 (random forest), 서포트 벡터 머신(support vector machiens) 등
-
폐암 수술 환자의 생존율 예측하기
-
예제 소스 : deep_code/01_My_First_Deeplearning.py
# -*- coding: utf-8 -*-
# 코드 내부에 한글을 사용가능 하게 해주는 부분입니다.
# 딥러닝을 구동하는 데 필요한 케라스 함수를 불러옵니다.
from keras.models import Sequential
from keras.layers import Dense
# 필요한 라이브러리를 불러옵니다.
import numpy
import tensorflow as tf
# 실행할 때마다 같은 결과를 출력하기 위해 설정하는 부분입니다.
seed = 0
numpy.random.seed(seed)
tf.set_random_seed(seed)
# 준비된 수술 환자 데이터를 불러들입니다.
Data_set = numpy.loadtxt("../\dataset/ThoraricSurgery.csv", delimiter=",")
# 환자의 기록과 수술 결과를 X와 Y로 구분하여 저장합니다.
X = Data_set[:,0:17]
Y = Data_set[:,17]
# 딥러닝 구조를 결정합니다(모델을 설정하고 실행하는 부분입니다).
model = Sequential()
model.add(Dense(30, input_dim=17, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# 딥러닝을 실행합니다.
model.compile(loss='mean_squared_error', optimizer='adam', metrics=['accuracy'])
model.fit(X, Y, epochs=30, batch_size=10)
# 결과를 출력합니다.
print("\n Accuracy: %.4f" % (model.evaluate(X, Y)[1]))
-
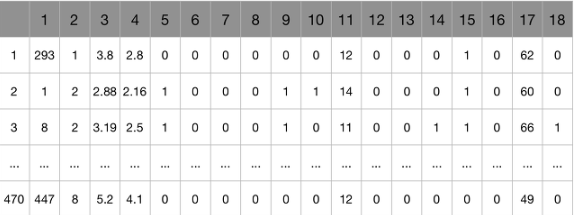
데이터 : dataset/ThararicSurgery.csv
-
첫 째 행, 1번 ~ 17번 : 속성
-
18번 : 클래스 (1: 수술 후 생존, 0 : 수술 후 사망)
[모두의 딥러닝] 03. 가장 훌륭한 예측선 긋기 : 선형 회귀
:: 딥러닝의 가장 밑 단에서 이루어지는 가장 기본적인 두 가지 계산 원리
:: 1. 선형 회귀
:: 2. 로지스틱 회귀
-
선형 회귀의 정의
-
1. "학생들의 중간고사 성적이 다 다르다."
-
2. 학생들의 중간고사 성적이 [ ]에 따라 다르다."
-
[ ] 부분 : 시험 성적을 좌우할 만한 것들, '정보'라고 한다.
-
x : '정보' 요소, 독립 변수
-
y : x값에 의해 변하는 '성적', 종속 변수
>> 단순 선형 회귀 (simple linear regression) : 하나의 x값만으로도 y값을 설명
>> 다중 선형 회귀 (multiple linear regression) : x값이 여러 개 필요할 떄
-
가장 훌륭한 예측선이란 ?
-
공부한 시간 x = { 2, 4, 6, 8} (단위 : 시간)
-
성적 y = { 81, 93, 91, 97 } (단위 : 점)

-
선은 직선, 일차 함수 그래프
-
y = ax + b
-
a 는 직선의 기울기, y값의 증가량 / x값의 증가량
-
b는 y축을 지나는 값인 'y 절편'
>> 선형 회귀 : 정확한 직선을 그려내는 과정
>>>> 최적의 a갑솨 b 값을 찾아내는 과정
'Deep Learning > Keras' 카테고리의 다른 글
| 케라스 기초 (0) | 2019.07.15 |
|---|
